
Multimodal AI Meets Handwriting: Text Conversion using Gemini AI
Experiment with GeminiAI's Multimodal Capabilities


What is Gemini AI?
It’s a new Multimodal AI with visual capabilities that Google recently released (in December 2023). It boasts impressive visual and inference capabilities, and we will be experimenting with its handwritten text extraction use case.
I wrote a previous article where we explored “Image text to json” and “Describe video content” uses cases, feel free to check it out.
What are we doing in this article?
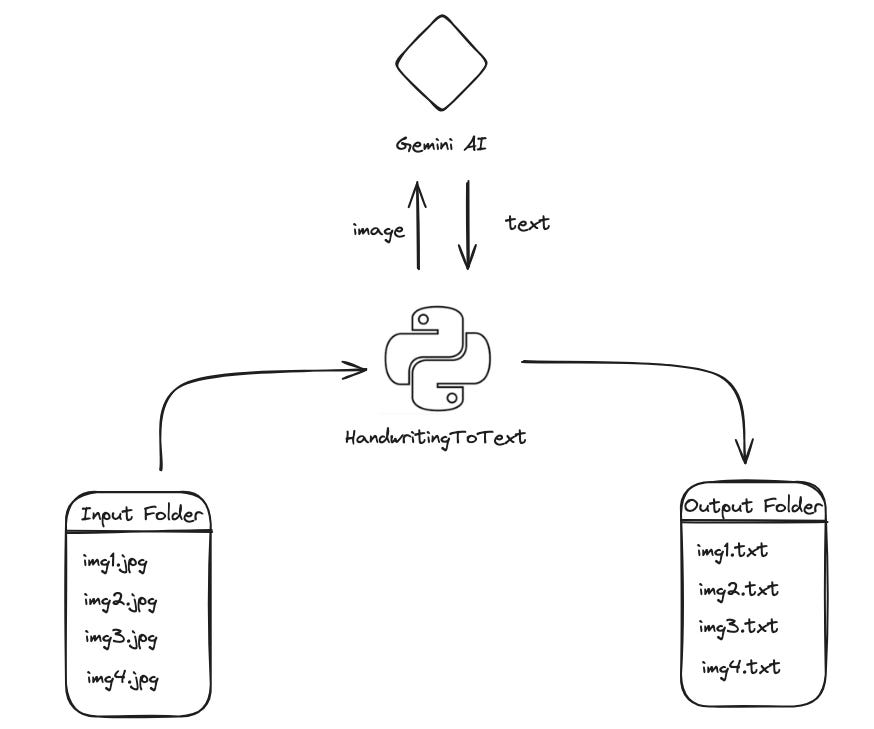
We’ll explore the handwritten text extraction capabilities of Gemini AI using the ‘Vision Pro’ model. Our approach involves creating a Python application that reads handwritten images from one folder (input) and writes the converted text files to another folder (output).
The Vision Pro model of GeminiAI is currently in developer preview, and all API calls to this model are free. Therefore, this is the ideal time to experiment with this API.
Is there a no code approach ?
Yes there is one atleast to just test the conversion with just 1 image:
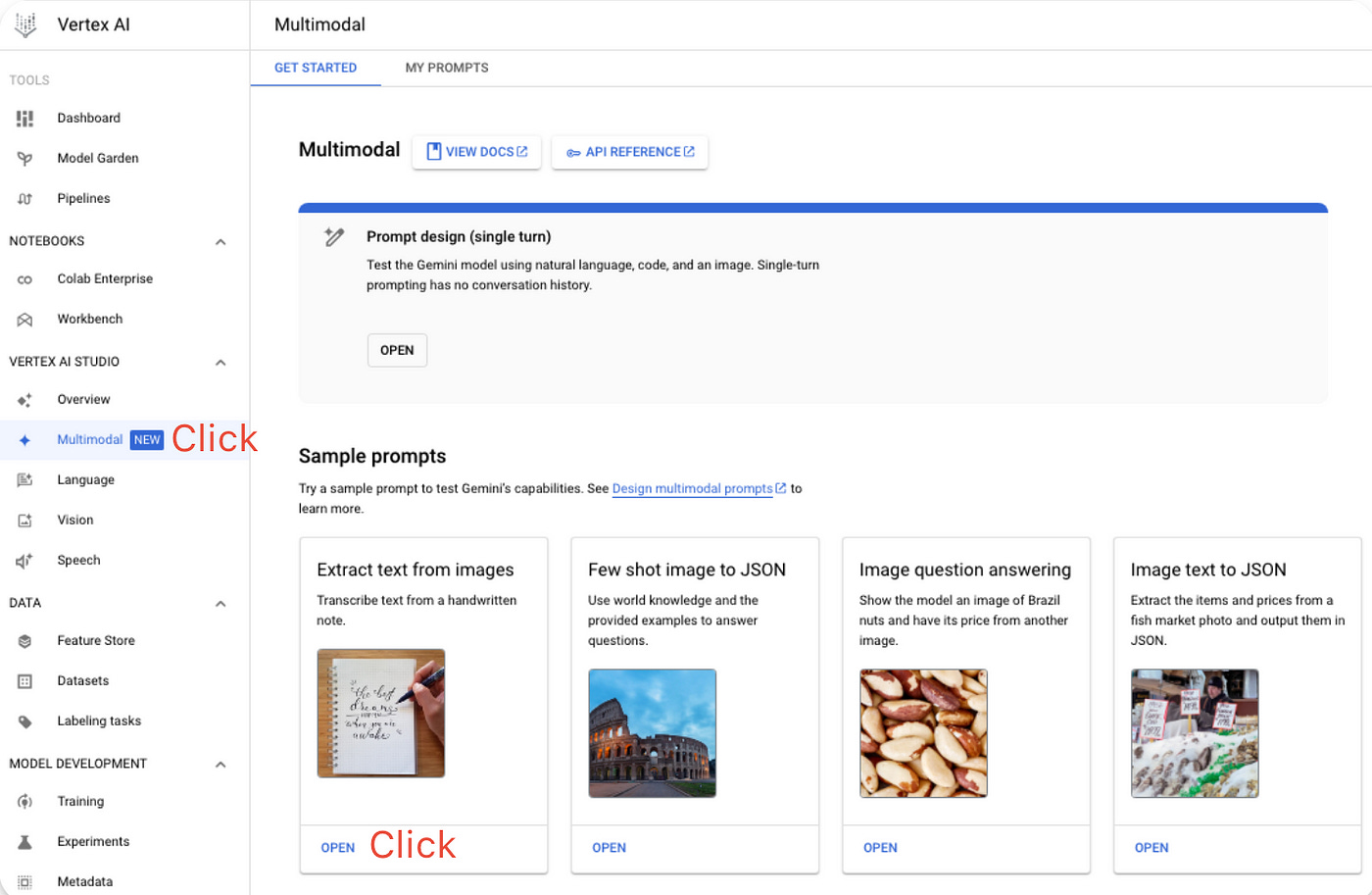
Go to Google Cloud and click on the ‘Go to Console’ button, which will open Vertex AI.
Click on ‘Multimodal’, and then on the ‘Extract text from images’ panel.
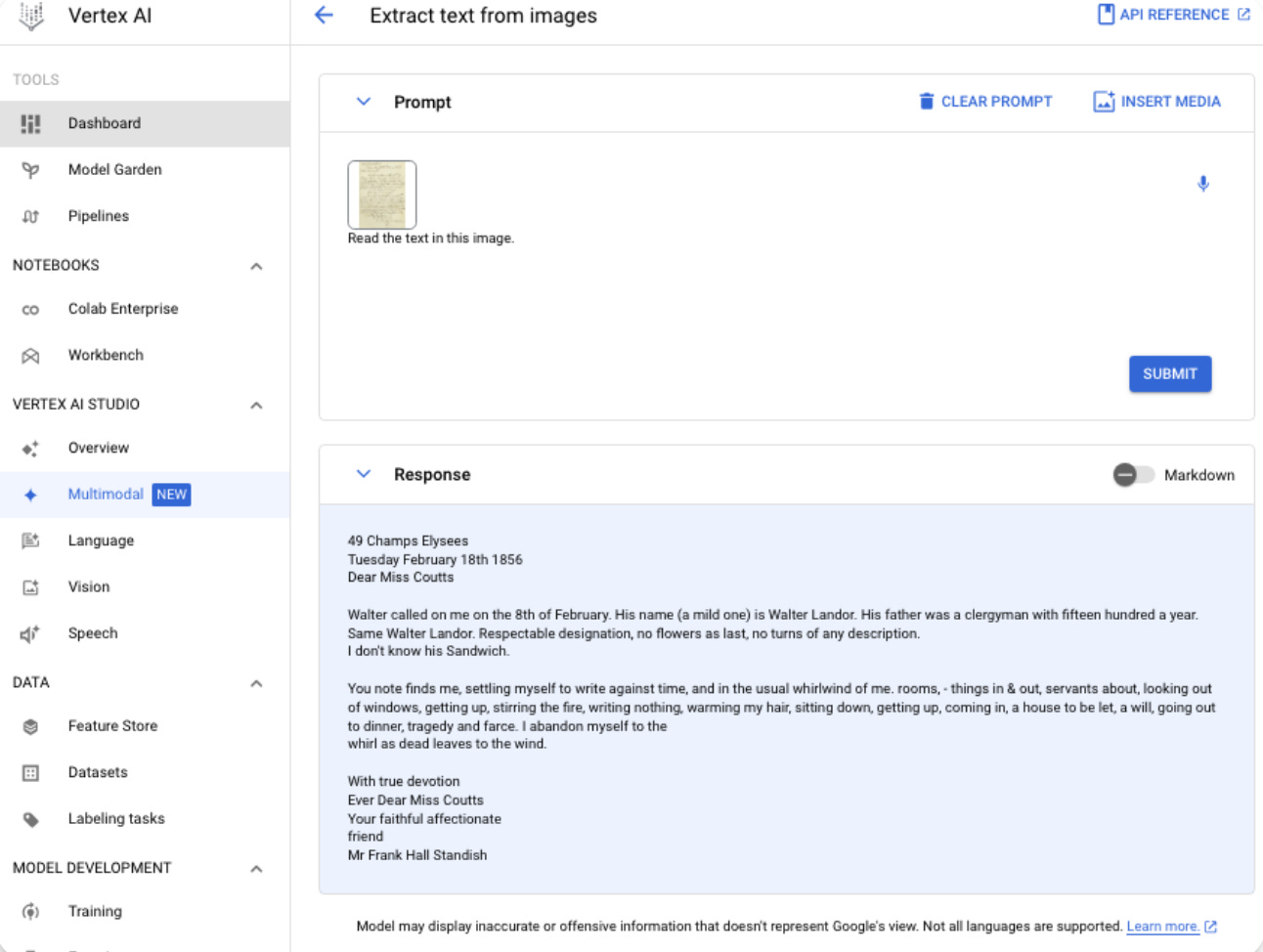
3. In the resulting window provide an image with handwritten text and you should see an output.
What if you are super busy and don’t have time to create this application?
You can clone the Python app from GitHub, update the input/output paths, and change the Vertex AI project name:

And run the project like below:
python main.pyGetting the data
For this application we would need some images for handwritten text, you can provide your own handwritten images. I have chosen Charles Dickens Letters that he wrote in 1800s and he wrote 14000! of them, checkout this wiki for more information. This is a sample of one of his letters, which I think is a good challenge to throw at Gemini AI.

Put the images in the input folder, and let’s get started with the implementation.
Implementation:
Prerequisites:
Jupyter → use Anaconda.
Python 3.11
Input Folder containing handwritten text images(jpg/png)
Implementation Steps:
Step 0: Install dependencies:
!pip install --upgrade google-cloud-aiplatform
!pip install PillowStep 1: Import Dependencies:
from PIL import Image
import os
import base64
from io import BytesIO
import vertexai
from vertexai.preview.generative_models import GenerativeModel, PartStep 2: Create a function to read images from folder
Here we are using Image from PIL(Python Image Library) to read the images in the input folder.
def read_images_from_folder(folder_path):
images = []
for filename in os.listdir(folder_path):
if filename.endswith(".jpg") or filename.endswith(".png"):
img = Image.open(os.path.join(folder_path, filename))
images.append((filename, img))
return imagesStep 3: Create a function to convert the images to base64 format
Gemini AI requires that the images be converted to base64 format, we are using base64 library to do that conversion.
def convert_to_base64(images):
base64_images = []
for filename, img in images:
buffered = BytesIO()
img.save(buffered, format="PNG") # Change format to "JPEG" if needed
img_base64 = base64.b64encode(buffered.getvalue()).decode('utf-8')
base64_images.append({'name': filename, 'base64': img_base64})
return base64_imagesStep 4: Create a function that calls the Gemini AI API to get a response for the base64 version of the image.
Here, we are passing standard configurations to the API, and if you look closely, you will see that we are streaming the response (stream = True). This means we will receive the response in multiple chunks, so we need to combine these responses to get a final output, which is what we are doing.
def generate(image):
combined_response = ""
image_decoded = Part.from_data(data=base64.b64decode(image), mime_type="image/jpeg")
model = GenerativeModel("gemini-pro-vision")
responses = model.generate_content(
[image_decoded, """Read the text in this image."""],
generation_config={
"max_output_tokens": 2048,
"temperature": 0.4,
"top_p": 1,
"top_k": 32
},
stream=True,
)
for response in responses:
#print(response.text, end="")
combined_response += response.text
return combined_responseStep 5: Create a function to save the response from Gemini AI as text files in a predefined folder.
Here, we are passing the final text for the image, along with its name and an output folder. We simply take the name, remove ‘jpg’ from it, and use the same name to map our output text files. This approach makes it easy for us to map the input with the output.
def save_text_to_files(text_for_images, predefined_folder):
# Create the folder if it doesn't exist
if not os.path.exists(predefined_folder):
os.makedirs(predefined_folder)
for item in text_for_images:
# Extract the image name (without extension) and Base64 string
image_name = os.path.splitext(item['name'])[0]
base64_string = item['text']
# Construct the full path for the text file
file_path = os.path.join(predefined_folder, image_name + '.txt')
# Write the Base64 string to the file
with open(file_path, 'w') as file:
file.write(base64_string)
print("handwritten text has been saved to text files.")Step 6: Calling the above functions in sequence
vertexai.init(project="project-name")
input_folder_path = 'path_to_images_with_handwritten_text'
output_folder_path = 'path_where_text_files_will_be_generated'
images = read_images_from_folder(input_folder_path)
base64_images = convert_to_base64(images)
text_for_images = []
for image in base64_images:
print(image['name']);
#print(image['base64']);
response = generate(image['base64'])
text_for_images.append({'name': image['name'], 'text': response})
save_text_to_files(text_for_images, output_folder_path)This is what we are doing in the code above:
Initiate Vertex AI with a project name, and then define the input and output folder paths. The input folder will contain the images that we want to convert to text, and these text files will be saved in the output folder.
Read the images from the input folder.
Convert these images into base64 format.
Iterate through these images and make calls to the generate() API to get a response from Gemini AI, and create an array with image text and name dictionary objects.
Finally, call the save_text_to_files() API, which will save the text in the respective files, named according to their original names.
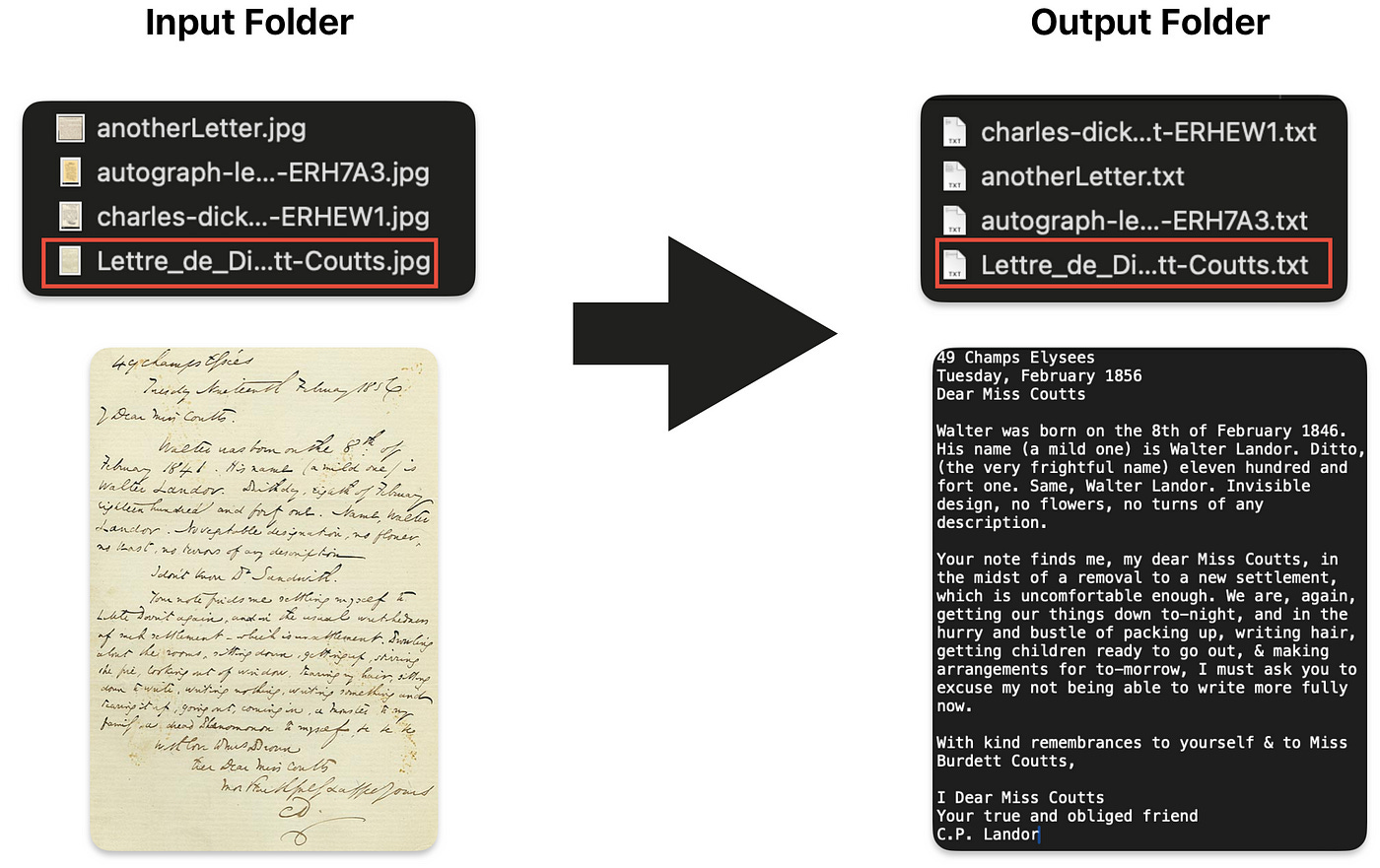
Final output
The output will look like the following: on the left, we have the handwritten images in the input folder, and on the right, the converted text in the output folder.
Conclusion
Understanding handwriting has always been tricky, right from the early days of writing. Machine learning experts have been working on this for a long time. Now, with new Large Language Models (LLMs) and better visual tools, it looks like we’re finally getting close to solving this. This ability could soon be something everyone can use. What are your ideas for using this technology? Let me know in the comments!
Code Resources:
🌟 Stay Connected! 🌟
I love sharing ideas and stories here, but the conversation doesn’t have to end when the last paragraph does. Let’s keep it going!
🔹 LinkedIn for professional insights and networking: https://www.linkedin.com/in/madhavengineer
🔹 Twitter for daily thoughts and interactions:https://twitter.com/MadhavAror
🔹 YouTube for engaging videos and deeper dives into topics: https://www.youtube.com/@aidiscoverylab
Got questions or want to say hello? Feel free to reach out to me at madhavarorabusiness@gmail.com. I’m always open to discussions, opportunities, or just a friendly chat. Let’s make the digital world a little more connected!