
Extracting Information from Google Drive Documents: A Gen AI Guide


Introduction
This guide provides instructions on how to retrieve information from documents stored in Google Drive.
The problem
We have a lot of documents, representing knowledge, stored in our Google Drives. Is it possible to query these documents and retrieve the information we need both quickly and efficiently?”
Approach
LangChain’s Question Answering use case offers a clean and quick solution to creating a RAG based solution for the above problem. Using Google Drive Document Loader, we’ll create a Document object(Langchain Schema), push it to a vector DB and then use the RetrievalQA chain to query on that Vector DB.

About Document Loaders
Document Loader is a LangChain component used to retrieve information from various data sources. This information is then converted to a format (Document object) that various chains (like RetrievalQA) in LangChain understand. There are several (around 168) Document Loaders, and Google Drive is one of them.
Sneak Peak into Google Drive Document Loader
Google Drive Loader from LangChain takes in a folder ID and has a flag to configure the behavior as either recursive or linear. For the first parameter, we provide a credentials file. This file is used to grant access to the Google Drive folder for your project and is required for authentication purposes.
GoogleDriveLoader(
gdrive_api_file="credentials.json",
folder_id="Your folder id",
# Optional: configure whether to recursively fetch files from subfolders. Defaults to False.
recursive=False
)Steps to get the credentials
Login to Google Cloud
Create a project if you don’t have one else move to the next step.
Click on “APIs and services” tile in the Quick Access section.

4. Go to “Credentials” section from the left pane.

5. Create a Service Account.
6. Click on the service account.
7. Go to “Keys” menu
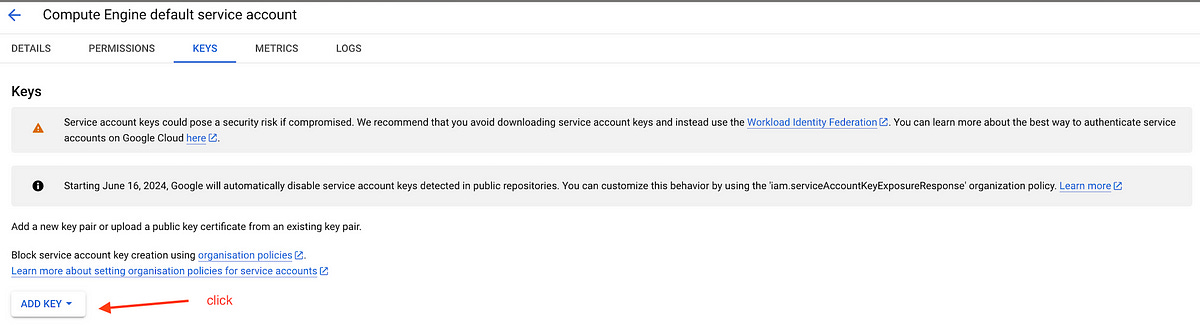
8. Click on “Create new Key”

9. A new json file will be downloaded.
10 Rename this file to “credentials.json” and save the path to it, we’ll need it at the time of implementation.
Implementation
Prerequisites
Credentials.json file available for your google service account.
Share your google drive folder with the Service Account Email, after you are done sharing, it should look something like below.

Don’t have time to go through the implementation?
Feel free to clone the Python app from GitHub, update the OpenAI key here and run the project:
Implementation Steps
In the implementation, we’ll define the functions for each operation and call them in sequence from the main function.

Step 0: Install the below dependencies
openai
tiktoken
chromadb
unstructured[all-docs]
langchain
langchain_openai
anthropic
langchain-anthropic
langchain-community
langchain-googledriveStep 1 : Set the openAI API Key
os.environ["OPENAI_API_KEY"] = "OpenAI API Key"The API keys for OpenAI can be obtained from the API Keys section of the OpenAI website.
Step 2: Import Google Drive Loader and other dependencies
import os
import argparse
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_googledrive.document_loaders import GoogleDriveLoaderStep 3 : Create a function for loading data from Google Drive, this would leverage Google Drive Loader introduced in the sections above.
def load_google_drive_data(folder_id):
loader = GoogleDriveLoader(
# provide the path to the credentials file, I have it in the project root.
gdrive_api_file="credentials.json",
folder_id=folder_id,
# Optional: configure whether to recursively fetch files from subfolders. Defaults to False.
recursive=False
)
loaded_data = loader.load()
print("loaded data ", loaded_data)
return loaded_dataStep 4 : Define a function for persisting data in a vector db, we are using ChromaDB.
def persist_data_in_chroma(persist_directory, data):
# various supported model options are available
embedding_function = OpenAIEmbeddings()
print('data: ', data)
# Chroma instance takes in a directory location, embedding function and ids-> list of documentIds
chroma_db = Chroma.from_documents(data,
embedding_function, persist_directory)
return chroma_dbStep 5: Define a function for initializing a Large Language Model API.
def create_llm(model_name, **kwargs):
# Map model names to their corresponding class constructors
model_map = {
"claude-3-sonnet-20240229": ChatAnthropic,
"gpt-3.5-turbo": ChatOpenAI,
"gpt-4o": ChatOpenAI,
# Add more models here
}
# Get the constructor for the given model_name or raise a ValueError if not found
model_constructor = model_map.get(model_name)
if model_constructor:
return model_constructor(model_name=model_name, **kwargs)
else:
raise ValueError("Unsupported model_name")I have a model map above, which maps to other models, I have tested this implementation on gpt-4o, feel free to experiment with other models.
Step 6: Create a function for querying on the Vector DB.
def query_data(db, llm, query):
print("summarizing data with llm : ", llm)
chatbot_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 1})
)
template = """
respond as clearly as possible and in max 200 words {query}?
"""
prompt = PromptTemplate(
input_variables=["query"],
template=template,
)
summary = chatbot_chain.run(
prompt.format(query=query)
)
return summaryIf you look closely, you’ll see we are passsing the db instance, llm instance and the respective query to this method.
Step 7: Define a function to process the arguments passed with the script. This is an optional steps, I am using it to pass the model name, and I have the corresponding map defined in “create_llm()” function, check Step 5 above for more details.
def process_args():
parser = argparse.ArgumentParser(description="Process model_name")
parser.add_argument('--model_name', type=str, help='The name of the model to use')
return parserStep 8: Call everything in sequence
if __name__ == '__main__':
args = process_args().parse_args()
model_name = args.model_name
folder_id = '1qzSNXYs3sey99SDxFvkLSPmOlQiL7zA3'
# Load the data from Google Drive
data = load_google_drive_data(folder_id)
# Persist the data in Chroma
db = persist_data_in_chroma('db', data)
# configure the respective model
llm = create_llm(model_name, temperature=0, max_tokens=500)
# TODO: Persist the db, and use that instance to query
response = query_data(db, llm, "tell me about the aviation research in 100 words ?")
print('response from model: ', response)Final Step : Trigger the app with the below command
python main.py --model_name gpt-4oTesting the implementation
I have the below documents in my Google Drive folders, which are just some research papers, you can have any document which can be extracted to a pdf.

To be precise the following mime types are supported:
text/text
text/plain
text/html
text/csv
text/markdown
image/png
image/jpeg
application/epub+zip
application/pdf
application/rtf
application/vnd.google-apps.document (GDoc)
application/vnd.google-apps.presentation (GSlide)
application/vnd.google-apps.spreadsheet (GSheet)
application/vnd.google.colaboratory (Notebook colab)
application/vnd.openxmlformats-officedocument.presentationml.presentation (PPTX)
application/vnd.openxmlformats-officedocument.wordprocessingml.document (DOCX)Query 1: Tell me about the aviation Result in 100 words

Query 2: Tell me about TimeBench ?

As you can see that it is able to retrieve information from the documents that I have in the google drive, I have just done it for pdf documents, feel free to experiment with other supported document types.
Conclusion
It was a fun experiment, and it demonstrates an incredible capability to uncover and learn from the information buried in your documents. This approach enhances efficiency and opens up new possibilities for data analysis and knowledge extraction, making our stored information more accessible and useful. Let me know in the comments what you would like to use it for!
🌟 Stay Connected! 🌟
I love sharing ideas and stories here, but the conversation doesn’t have to end when the last paragraph does. Let’s keep it going!
🔹 LinkedIn for professional insights and networking: https://www.linkedin.com/in/madhav-arora-0730a718/
🔹 Twitter for daily thoughts and interactions:https://twitter.com/MadhavAror
🔹 YouTube for engaging videos and deeper dives into topics: https://www.youtube.com/@aidiscoverylab
Got questions or want to say hello? Feel free to reach out to me at madhavarorabusiness@gmail.com. I’m always open to discussions, opportunities, or just a friendly chat. Let’s make the digital world a little more connected!